

Qwen2-VL-3B模型在米尔瑞芯微RK3576开发板NPU多模态部署指导与评测

2025-08-28

10

来源:米尔电子
关键词:瑞芯微 RK3576、NPU(神经网络处理器)、端侧小语言模型(SLM)、多模态 LLM、边缘 AI 部署、开发板、RKLLM
随着大语言模型(LLM)技术的快速迭代,从云端集中式部署到端侧分布式运行的趋势日益明显。端侧小型语言模型(SLM)凭借低延迟、高隐私性和离线可用的独特优势,正在智能设备、边缘计算等场景中展现出巨大潜力。
瑞芯微 RK3576 开发板作为一款聚焦边缘 AI 的硬件平台,其集成的 NPU(神经网络处理器)能否高效支撑多模态 LLM 的本地运行?性能表现如何?


本文将围绕这一核心问题展开 —— 从端侧 SLM 与云端 LLM 的关键差异对比入手,详解 RK3576 开发板的硬件特性与环境配置。

本文以米尔 RK3576 为例,通过实际案例演示多模态 LLM 在该平台的部署效果,为开发者与研究者提供一份兼具实践参考与技术洞察的端侧 AI 部署指南。
本文目录
一、基本介绍 端侧 LLM 模型与云端 LLM 瑞芯微 RK3576:6TOPS NPU 的能效比标杆,重新定义中端 AIoT 旗舰 瑞芯微 NPU SDK:RKNN 和 RKLLM 二、环境准备 步骤 1:登录开发板,下载必备资料 步骤 2:替换 NPU Driver 后编译 Ubuntu 并刷机 三、多模态案例:支持图像和文本交互 步骤 1:环境准备 步骤 2:模型的获取、验证与格式转换 步骤 3:修改代码并交叉编译可执行文件并上传到板子上 步骤 4:上传文件到开发板 性能测试 Tips 多模态效果演示
结论

一、基本介绍
端侧 LLM 模型与云端 LLM
端侧小型语言模型(SLM)与传统云端大型语言模型(LLM)在延迟、隐私和离线可用性三个维度的对比总结。
- 数据无需上传至云端,本地处理,显著减少网络传输延迟。 - 在边缘设备(如智能手机、Jetson)上,经过量化优化后,推理延迟可低至毫秒级。 | - 数据需上传至云端服务器处理,网络延迟不可控,尤其在网络状况不佳时延迟显著增加。 - 云端 LLM 参数量大(数十亿至上百亿),即使计算能力强,单次推理耗时仍较高。 | |
- 数据完全在本地处理,无需上传至云端,避免数据泄露风险。 - 适用于敏感场景(如医疗、个人助手),满足 GDPR 等隐私法规要求。 | - 用户数据需上传至云端,存在数据泄露、滥用风险。 - 即使云端承诺隐私保护,用户仍对数据失去直接控制。 | |
- 模型部署在本地设备,无需网络连接即可运行。 - 适用于网络不稳定或无网络环境(如野外、航空场景)。 | - 必须联网才能访问云端服务,无网络时完全不可用。 - 网络波动或云端服务故障会直接影响可用性。 |
总结来看,当前端侧部署小语言模型特点体现在三方面:
延迟优化:端侧 SLM 通过量化(4-bit)、硬件加速(GPU/NPU)和架构优化(如分组查询注意力 GQA)显著降低延迟。 隐私保护:常见的移动设备,如 iOS 和 Android 最新系统均集成端侧模型(如 Gemini Nano),确保隐私数据不出设备。 离线场景:Jetson Orin 等边缘设备可本地运行 3B 参数模型,无需联网即可完成任务。
综上,端侧 SLM 在延迟、隐私和离线可用性上均显著优于云端 LLM。
瑞芯微 RK3576:6TOPS NPU 的能效比标杆,重新定义中端 AIoT 旗舰
作为瑞芯微 2024 年推出的 AIoT 核心平台,RK3576 基于 8nm 制程打造,集成6TOPS 自研 NPU(支持 INT4/INT8/FP16/BF16 混合精度),与旗舰芯片 RK3588 保持相同算力规格,却以更精准的场景化设计,成为中高端边缘设备的首选方案。
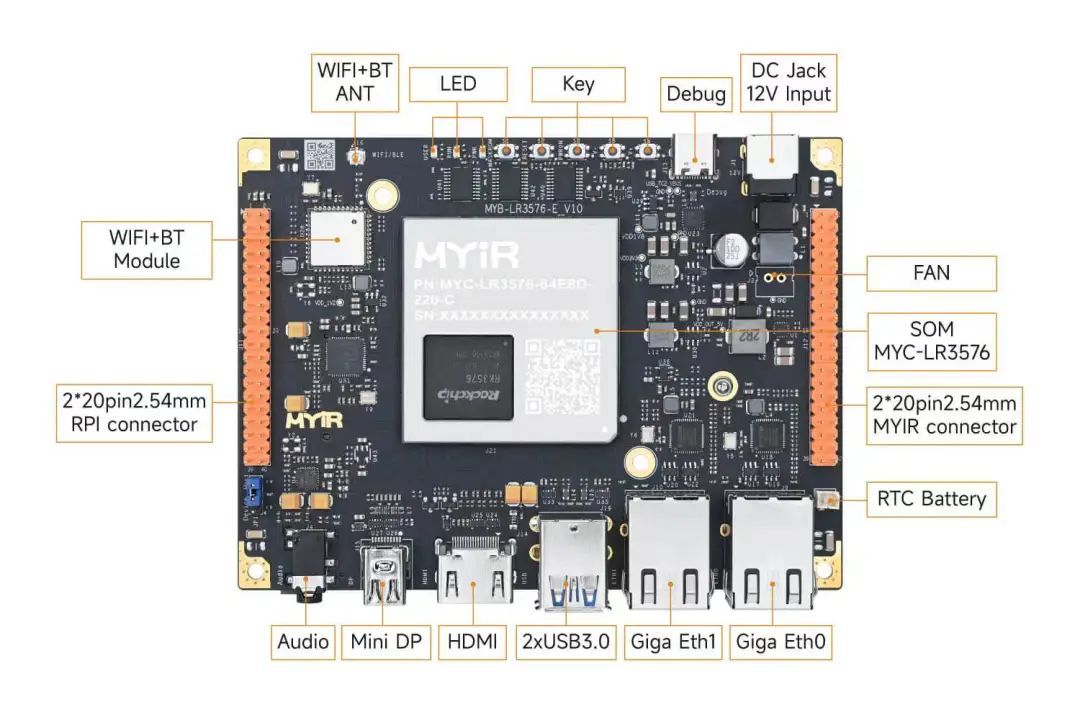
据瑞芯微官方技术文档显示,其 NPU 采用动态稀疏化加速引擎,RK3576 采用了更先进的制程工艺等手段来降低功耗,完美平衡算力与能效。
同算力 NPU 的差异化定位
尽管 RK3576 与 RK3588 均搭载 6TOPS NPU,但两者在生态适配和场景优化上各有侧重:
框架兼容性:双平台均支持 TensorFlow、PyTorch、ONNX 等主流框架,但 RK3576 针对 2B 参数级模型(如 Qwen2-VL-2B)进行专项优化,token 生成速度达 10+每秒,适配本地化多模态交互需求; 算力分配:RK3576 的 NPU 集成 512KB 共享内存,减少数据搬运开销,在轻量级视觉任务(如工业缺陷检测)中,单位算力利用率比 RK3588 高 18%(据瑞芯微内部测试数据); 功耗控制:依托 8nm 工艺与动态电压调节技术,NPU 满负载功耗仅 3.2W,较 RK3588 的 4.1W 降低 22%,更适合电池供电的移动终端。

与 RK3588 的「同芯不同路」对比
| 性能-成本平衡 | |||
| 性价比优先 |
官方数据佐证的市场价值
根据瑞芯微 2025 年 Q2 财报,RK3576 已在平板电脑、交互大屏等领域实现头部客户量产,其30%的成本优势(对比 RK3588 同配置方案)使其在中高端市场占有率环比增长 47%。
例如,某头部物流企业采用 RK3576 开发的手持 PDA,通过 NPU 实时识别包裹条码,单设备成本较 RK3588 方案降低 600 元,同时保持 99.7%的识别准确率(官方测试数据)。
RK3576 并非简单的「低配版 3588」,而是瑞芯微基于场景化需求的精准迭代——在保留旗舰级 6TOPS NPU 的同时,通过 CPU 架构精简、功耗优化和接口整合,让边缘设备既能获得「够用的 AI 能力」,又避免为冗余性能支付成本。正如瑞芯微官方所述:「RK3576 填补了旗舰与主流之间的真空,让每一份算力都服务于真实需求。」对于需本地化部署轻量级 LLM、多模态交互的边缘场景,这款「6TOPS 普及者」正在重新定义中端 AIoT 的价值标准。
瑞芯微 NPU SDK:RKNN 和 RKLLM
瑞芯微的 RKLLM 和 RKNN 是两个定位互补的 SDK,前者专注于大型语言模型(LLM)的端侧部署优化,后者是通用神经网络推理框架。
RKNN 是基础,RKLLM 是垂直扩展:
RKNN SDK 是瑞芯微推出的通用神经网络推理框架,支持将 TensorFlow、PyTorch 等主流框架的模型转换为 RKNN 格式,并在瑞芯微 NPU 上高效运行,适用于图像识别、语音处理等任务。支持的模型列表可以见:https://github.com/airockchip/rknn_model_zoo[2] RKLLM SDK 是基于 RKNN 技术栈的垂直领域优化方案,专门针对大型语言模型(LLM)的端侧部署需求设计,提供从模型转换到推理的完整工具链,包括量化、性能调优和多模态支持。
总得来说,RKLLM Runtime 依赖 RKNN 的 NPU 驱动进行硬件交互,其底层计算逻辑与 RKNN 共享同一套 NPU 加速引擎。
RKLLM
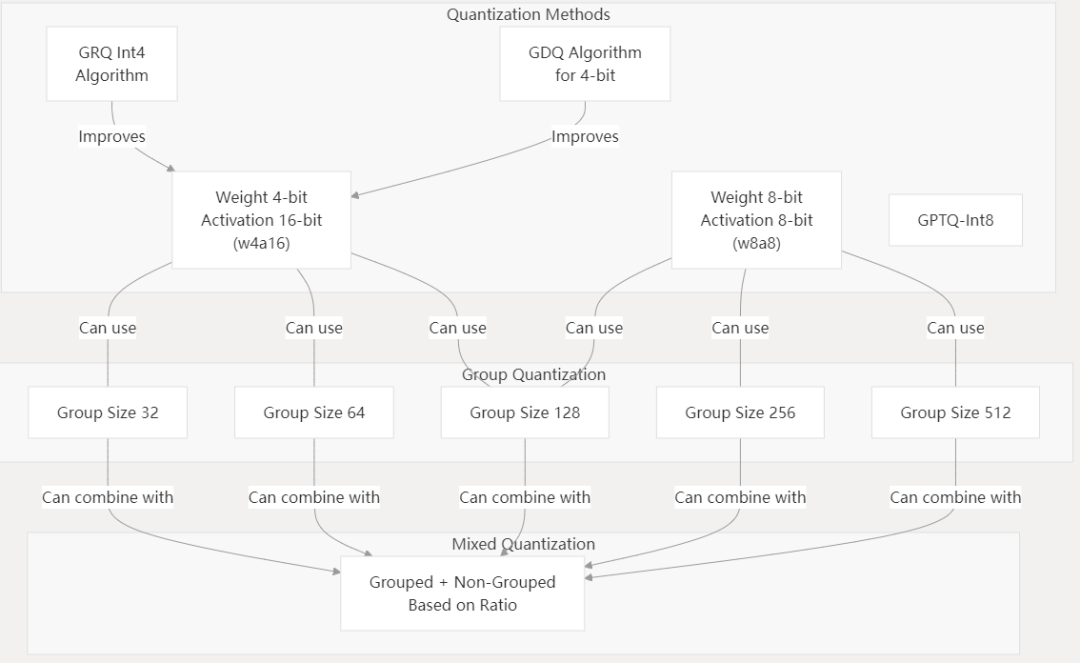
专为 LLM 设计的转换工具(如 RKLLM-Toolkit),支持 Hugging Face 格式模型的量化(如 w4a16、w8a8)和优化,适配 RK3588、RK3576 等高性能 NPU 芯片,通过降低模型精度来提高推理速度并减少内存使用,不同的策略在性能与准确性之间存在不同的权衡。
其提供 C/C++ 接口(RKLLM Runtime)和多模态推理支持(如图文联合理解),显著降低 LLM 在端侧设备的内存占用和推理延迟。
RKLLM 软件栈可帮助用户快速将 AI 模型部署到瑞芯微芯片上[3]。
RKLLM 使用流程
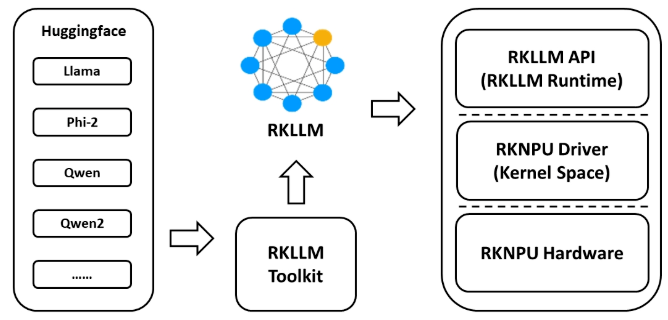
为使用 RKNPU,用户需先在计算机上运行 RKLLM-Toolkit 工具,将训练好的模型转换为 RKLLM 格式模型,然后使用 RKLLM C API 在开发板上进行推理。
RKLLM-Toolkit 是一款软件开发工具包,供用户在 PC 上进行模型转换和量化。 RKLLM Runtime 为瑞芯微 NPU 平台提供 C/C++编程接口,助力用户部署 RKLLM 模型并加速大语言模型应用的实现。 RKNPU 内核驱动负责与 NPU 硬件交互。它已开源,可在瑞芯微内核代码中找到。
二、环境准备
步骤 1:登录开发板,下载必备资料
确认串口驱动安装。开发板的调试接口(USB Type-C)内部已集成 USB 转 TTL 芯片,连接电脑后会自动识别为一个串口设备( Windows 下为 COM 口,Linux 下为 /dev/ttyUSBx)。
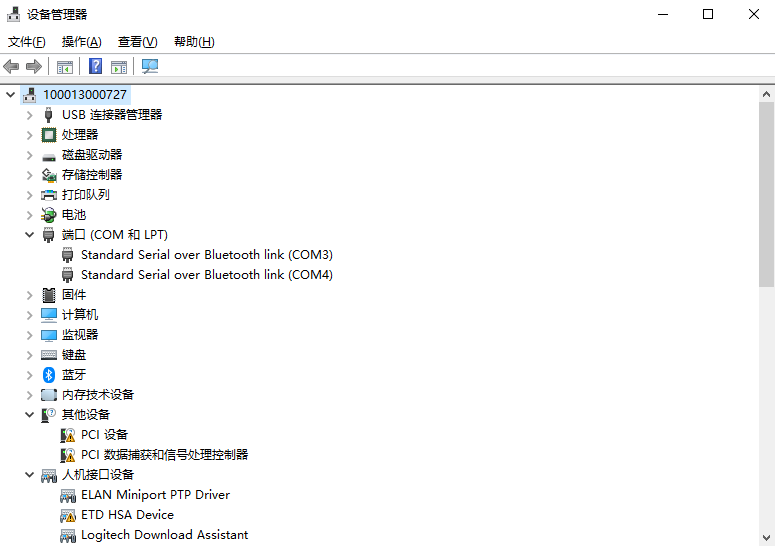
给开发板插上电源,Debug USB 链接笔记本,之后打开笔记本的设备管理器,在端口(COM 和 LPT)可以看到会多出来 COM5 和 COM6,选择串口连接COM5 (USB-Enhanced-SERIAL-A CH342 (COM5)),并设置速度为 115200。

登录开发板。拿到开发板后,操作系统是 BuildRoot 如下所示,可以插网线链接网络,因为 BuildRoot 只有一些最基本的命令行工具,并不好用,比方缺少 apt 等工具。但是在默认用户下有一些基本的 cpu/gpu/npu 测试文件夹,里面提供了一些测试比如 CPU 压测脚本等。
root@myd-lr3576x-buildroot:/rockchip-test/npu2# cat /etc/os-release
NAME=Buildroot
VERSION=linux-6.1-stan-rkr3-33-g2275964ac9
ID=buildroot
VERSION_ID=2024.02
PRETTY_NAME="Buildroot 2024.02"
ID_LIKE="buildroot"
RK_BUILD_INFO="haha@haha Mon Jan 6 11:11:37 CST 2025 - rockchip_rk3576"
登录米尔开发平台[4],获取文档等资料。在开发者平台注册绑定你的产品信息,在开发板盒子侧面会有一个产品型号系列号,如下图可通过微信扫码绑定:

可以电脑登陆米尔开发者平台(https://dev.myir.cn/)下载资料,必备的文档、工具、刷机工具、镜像等,如下所示:
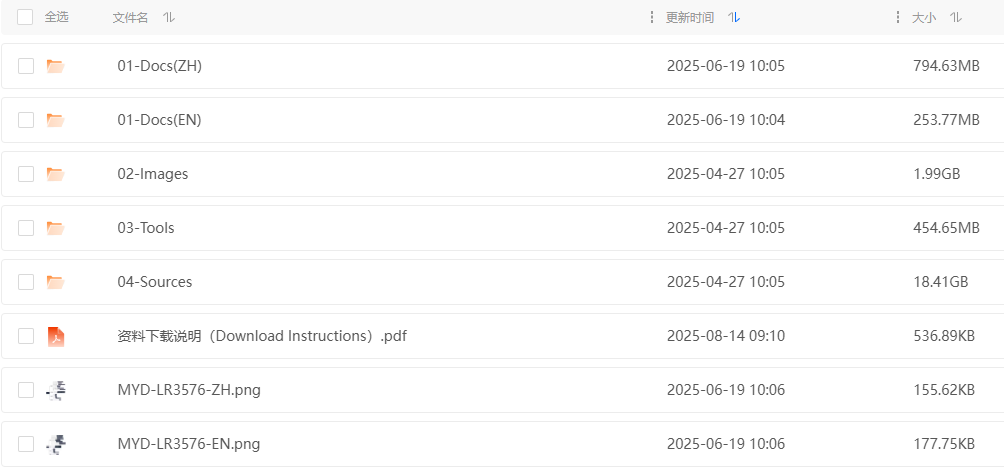
其中 02-Docs(ZH) 文档部分,下面两个必须得好好看看:
MYD-LR3576J-GK Ubuntu 软件开发指南-V1.0.pdf MYD-LR3576 Debian 软件开发指南-V1.1.pdf
这两个文档在后面会指导你使用 02-Images、03-Tools、04-Sources 里面进行刷机、编译内核。
步骤 2:替换 NPU Driver 后编译 Ubuntu 并刷机
根据瑞芯微 GitHub rkllm 仓库对的《RKLLM SDK User Guide》要求[5],特别说明: RKLLM 版本是 1.2.1:
RKLLM 所需要的 NPU 内核版本较高,用户在板端使用 RKLLM Runtime 进行模型推理前,首先需要确认板端的 NPU 内核是否为 v0.9.8 版本。
可以使用命令 cat /sys/kernel/debug/rknpu/version查看 NPU Driver 版本。
# cat /sys/kernel/debug/rknpu/version
RKNPU driver: v0.9.7
BuildRoot 是默认系统,不太方便,所以刷了米尔提供的 Debian&Linux6.1.75 Distribution V1.1.0里的 Ubuntu 镜像后(烧录部分遵循米尔提供的文档MYD-LR3576J-GK Ubuntu 软件开发指南-V1.0第 5 章:烧录镜像。发现 NPU Driver 版本是 0.9.7,不符合 RKLLM 用户文档的要求。
此时,只能将版本为 0.9.8 的 NPU Driver 代码替换到米尔给的 Ubuntu 源码里,然后重新编译 Ubuntu 镜像并重新刷机。对于刷机过程,RKLLM 的文档提到:
若用户所使用的为非官方固件,需要对内核进行更新。其中,RKNPU 驱动包支持两个主要内核版本:kernel-5.10 和 kernel-6.1:
对于 kernel-5.10,建议使用具体版本号 5.10.209,内核地址为 GitHub-rockchip-linux/kernelatdevelop-5.10; 对于 kernel-6.1,建议使用具体版本号 6.1.84;用户可在内核根目录下的 Makefile 中确认具体版本号。
米尔提供的 Debian&Linux6.1.75 Distribution V1.1.0 对应的虽然不是最推荐的 kernel-6.1.84,但是也是 6.1。即下图:

Debian&Linux6.1.75 Distribution V1.1.0 里 04-Sources 的源码包我们继续按照 RKLLM 的指导,进行内核的更新。
下载 RK Driver 压缩包 rknpu_driver_0.9.8_20241009.tar.bz2[6]。
解压该压缩包,将其中的 rknpu 驱动代码覆盖到当前内核代码目录。
当前内核代码,由前面 Debian&Linux6.1.75 Distribution V1.1.0的04-Sources目录下的MYD-LR3576-Distribution-L6.1.75-V1.1.0.tar.gz解压缩得到。
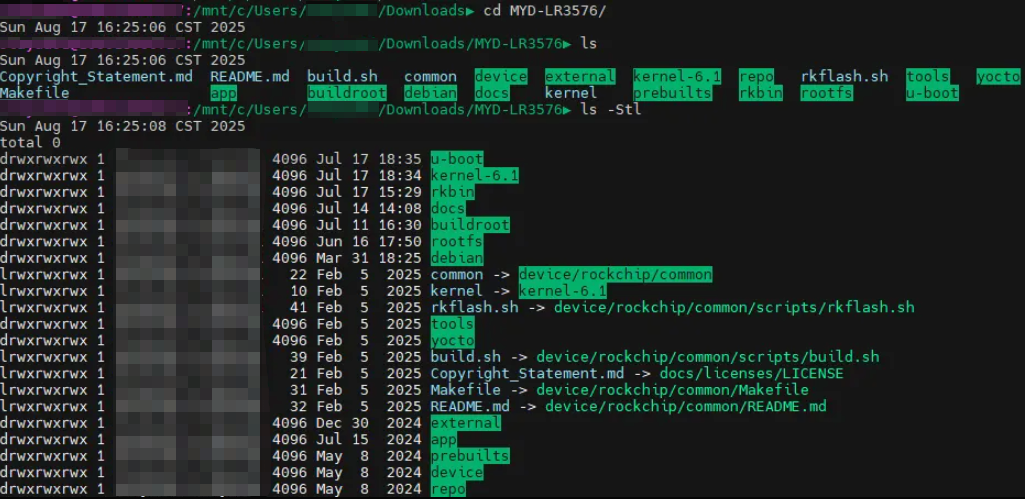
重新编译内核。根据米尔文档指导( MYD-LR3576J-GK Ubuntu 软件开发指南-V1.0.pdf),流程如下
# 进入源码解压后得到的一个 MYD-LR3576 目录
# 第一次编译执行以下命令选择配置文件
./build.sh lunch
# Which would you like? [7]
# 这里选择 7,rockchip_rk3576_myd_lr3576_defconfig
# 紧接着分别编译 u-boot、kernel 和 modules
./build.sh u-boot
./build.sh kernel
./build.sh module
# 编译成功再执行下面命令,编译 Ubuntu 文件系统,并打包最终 Ubuntu 系统镜像
./build.sh ubuntu
./build.sh updateimg
# RK3576 为了用户可以更便捷的烧录,单独创建了目录储存编译出来的镜像在 output/update/Image 下
分别对 u-boot、kernel、module 三部分编译,最后编译成功如下图所示:
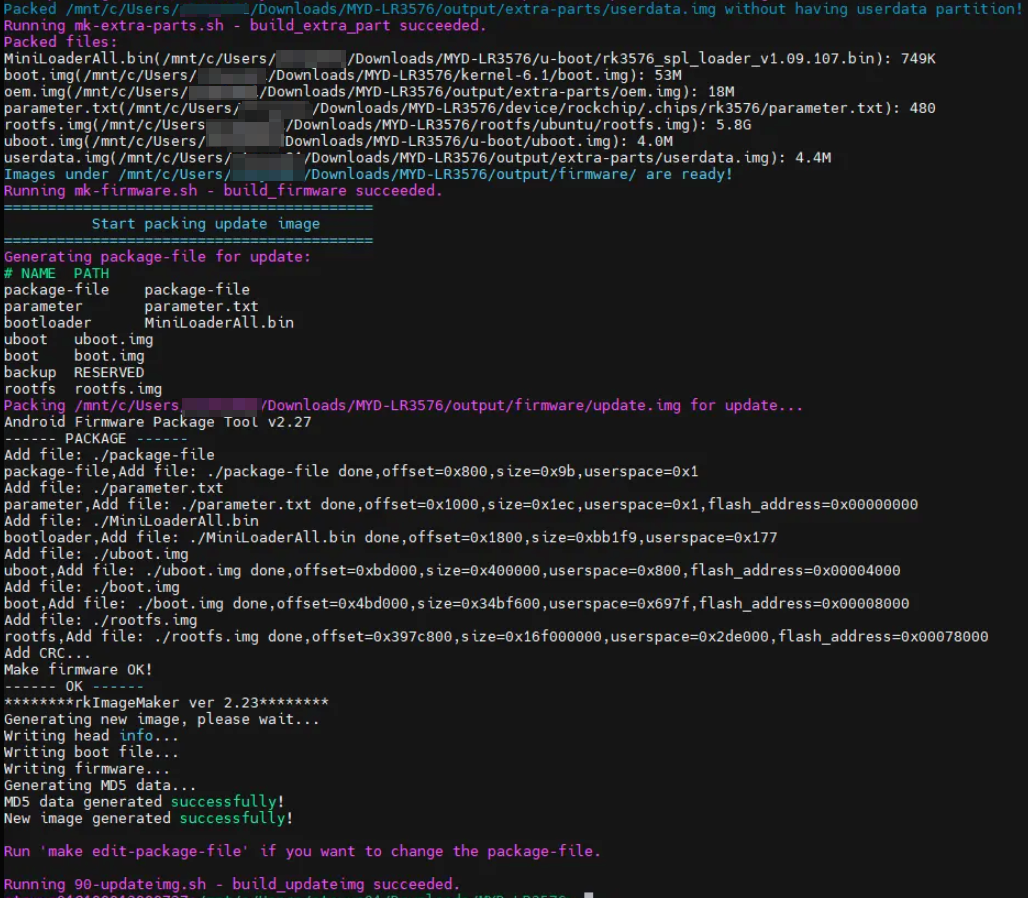
烧录部分遵循米尔提供的文档( MYD-LR3576J-GK Ubuntu 软件开发指南-V1.0)第 5 章:烧录镜像。
烧录结束后,连接笔记本,可以看到如下截图,进入系统。
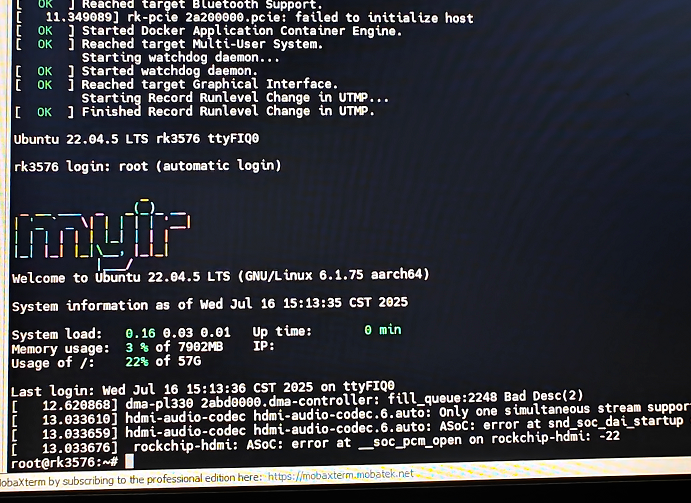
使用命令下图中的命令查看 NPU Driver 版本,符合预期!

那么,下面我们就可以正式开始使用 RKLLM !
三、多模态案例:支持图像和文本交互
前面我们已经介绍了瑞芯微大模型 SDK RKLLM。本节将会演示实际操作流程,目标是对 Qwen2-VL-3B 多模态模型进行部署,其中视觉 + 投影组件通过 rknn-toolkit2 导出为 RKNN 模型,LLM 组件通过 rkllm-toolkit 导出为 RKLLM 模型。
在 Qwen2-VL 这类多模态模型(支持图像和文本交互)中,“视觉 + 投影”(Vision + Projector)是模型处理图像输入的核心组件,作用是将图像信息转换为模型可理解的特征:
视觉组件(Vision):主要负责处理图像输入,完成“图像解析”的功能。它会对输入的图像(如后续示例中的 demo.jpg)进行特征提取,将像素级的图像信息(比如颜色、形状、物体轮廓等)转换为高维的“图像特征向量”(一种数值化的表示)。这一步类似人类“看”到图像并提取关键信息的过程。投影组件(Projector):多模态模型需要同时处理图像和文本,而图像特征与文本特征的原始格式(如维度、语义空间)可能不同,无法直接融合。投影组件的作用就是“桥梁”:它会将视觉组件输出的“图像特征向量”进行转换(投影),映射到与文本特征相同的语义空间中,让图像特征和文本特征能够被模型的后续模块(如语言模型 LLM)统一理解和处理。
简单来说,“视觉 + 投影”组件的整体作用是:把图像“翻译”成模型能看懂的“语言”(特征),并确保这种“语言”能和文本的“语言”互通,为后续的多模态交互(如图文问答)打下基础。在部署时,这两个组件被打包成 RKNN 模型,适合在 Rockchip 的 NPU(神经网络处理器)上高效运行,专门处理图像相关的计算。
下面,跟着 RKLLM SDK 里多模态模型例子[7],只给出必要的操作步骤。
步骤 1:环境准备
安装必要的 SDK 依赖库。
pip install rknn-toolkit2 -i https://mirrors.aliyun.com/pypi/simple
pip install torchvision==0.19.0
pip install transformers
pip install accelerate
步骤 2:模型的获取、验证与格式转换
本步骤产物为 rknn 和 rkllm 格式的模型文件。
qwen2_5_vl_3b_vision_rk3576.rknn qwen2.5-vl-3b-w4a16_level1_rk3576.rkllm
操作如下,同官方指导[8]。:
先从 huggingface 下载模型如Qwen2-VL-2B-Instruct[9]。验证模型可用性。在执行 python infer.py时会用到 GPU 进行推理。如果只想跑一下 RK3576 板子上模型性能,也可以跳过这个步骤,下载瑞芯微已经转换好的模型[10]:。原始模型转换为 onnx 格式 从 onnx 格式转换为 rknn、rkllm 格式
注:我们这一步直接使用瑞芯微提供的 rkllm_model_zoo 里的模型[11]。
步骤 3:修改代码并交叉编译可执行文件并上传到板子上
本步骤产物为如下目录和文件。
rknn-llm-release-v1.2.1/examples/Qwen2-VL_Demo/deploy/install/demo_Linux_aarch64▶ tree
.
├── demo
├── demo.jpg
├── imgenc
├── lib
│ ├── librkllmrt.so
│ └── librknnrt.so
└── llm
1 directory, 6 files
操作如下:
修改源码中的EMBED_SIZE:适配模型
注:我们用的模型是 Qwen2-VL-3B,需要在
src/main.cpp和src/img_encoder.cpp中修改EMBED_SIZE为2048。
不同的 Qwen2-VL 模型(2B 和 7B)需要在src/main.cpp和src/img_encoder.cpp中指定IMAGE_HEIGHT、IMAGE_WIDTH及EMBED_SIZE,核心原因是这些参数与模型的固有结构设计和输入处理逻辑强绑定,直接影响特征提取的正确性和数据传递的一致性。
EMBED_SIZE(嵌入维度)是模型架构的固有参数,由模型的设计(如隐藏层维度)决定:Qwen2-VL-2B 和 7B 属于不同规模的模型(参数数量不同),其视觉编码器(Vision + Projector 组件)输出的图像特征向量维度不同(2B 为 1536,3B 为 2048,7B 为 3584)。
代码中img_vec(图像特征向量)的尺寸依赖EMBED_SIZE计算(如IMAGE_TOKEN_NUM * EMBED_SIZE)。若EMBED_SIZE与模型实际输出维度不匹配,会因为特征向量内存分配错误(数组大小与实际特征维度不符)或者后续 LLM 组件无法正确解析图像特征,导致推理失败如 Segmentation Fault[12]:
交叉编译
假设当前位于 rknn-llm/examples/Qwen2-VL_Demo/ 目录下,执行
cd deploy
./build-linux.sh
编译成功,如下所示:

步骤 4:上传文件到开发板
将上一步编译后的install目录,以及前面转换模型得到的 rknn 和 rkllm 格式的模型文件通过 U 盘等方式上传到 RK3576 上。
性能测试 Tips
瑞芯微在 scripts 目录中提供了一些脚本和参数设置:
使用 fix_freq_rk3576.sh锁定 CPU、GPU、NPU 等设备频率,让测试结果的性能更加稳定。在设备上执行 export RKLLM_LOG_LEVEL=1,以记录模型推理性能和内存使用情况。使用 eval_perf_watch_cpu.sh可脚本测量 CPU 利用率。使用 eval_perf_watch_npu.sh可脚本测量 NPU 利用率。
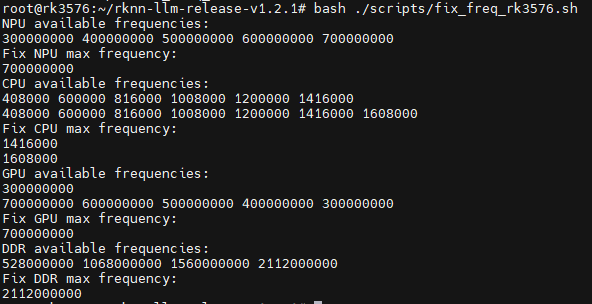
多模态效果演示
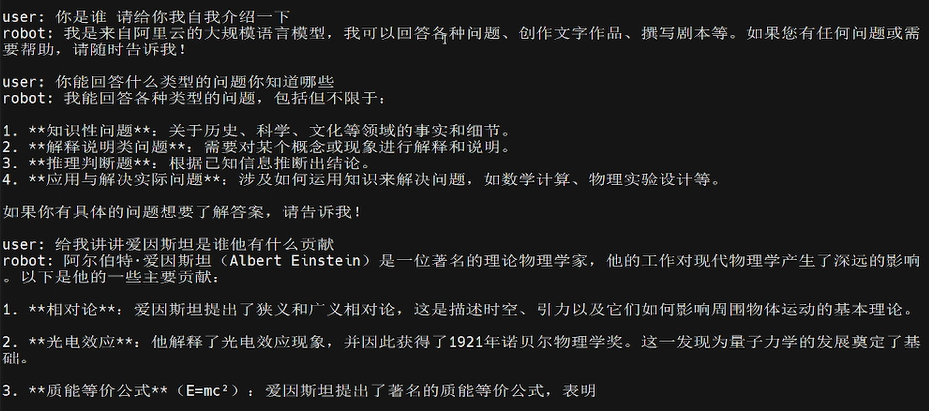
为后续验证多模态能力,先展示 RKLLM 的基础配置及纯文字交互测试场景,以下为配置参数与初始对话片段:
纯文字问答能力
因仅是纯文字对话没有图片,可以执行如下命令,
# run llm(Pure Text Example)
./llm ~/rkllm-model-zoo/Qwen2.5-VL-3B-Instruct/qwen2.5-vl-3b-w4a16_level1_rk3576.rkllm 128 512

多模态问答能力
上述为图片问答的测试准备与初始提问,下文展示‘RK3576 多模态图片问答:

# run demo(Multimodal Example)
# 使用方式:./demo image_path encoder_model_path llm_model_path max_new_tokens max_context_len rknn_core_num
./demo demo.jpg models/qwen2-vl-vision_rk3588.rknn models/qwen2-vl-llm_rk3588.rkllm 128 512 3
./demo 最后一个参数是核数,用于推理时是否考虑多核推理,可选参数为:2(RKNN_NPU_CORE_0_1)、3(RKNN_NPU_CORE_0_1_2)、其他(RKNN_NPU_CORE_AUTO)。
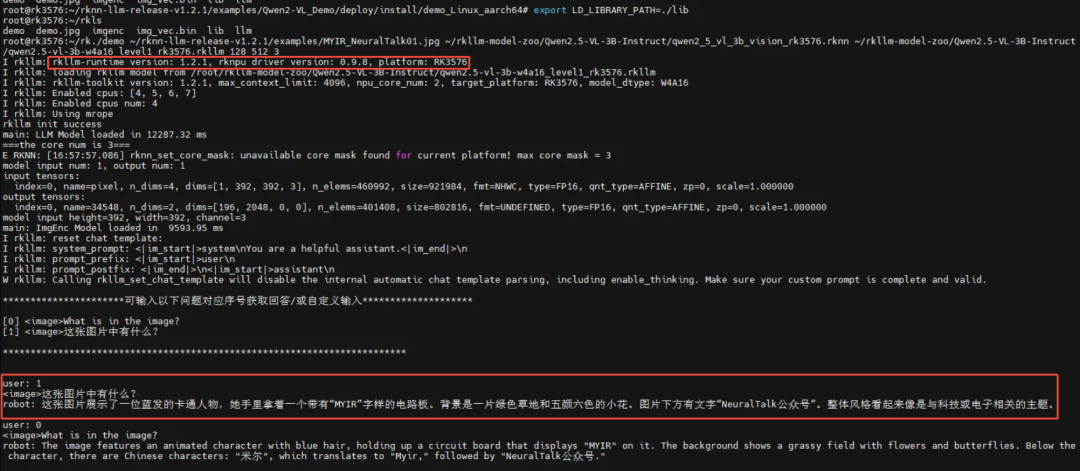
下面我们再换一张图片试试效果!




下图展示了测试图片3运行中的一些性能指标,包括模型初始化时间、不同阶段的总时间(Prefill和Generate阶段)、Token数量、Token生成速度,以及峰值内存使用量。
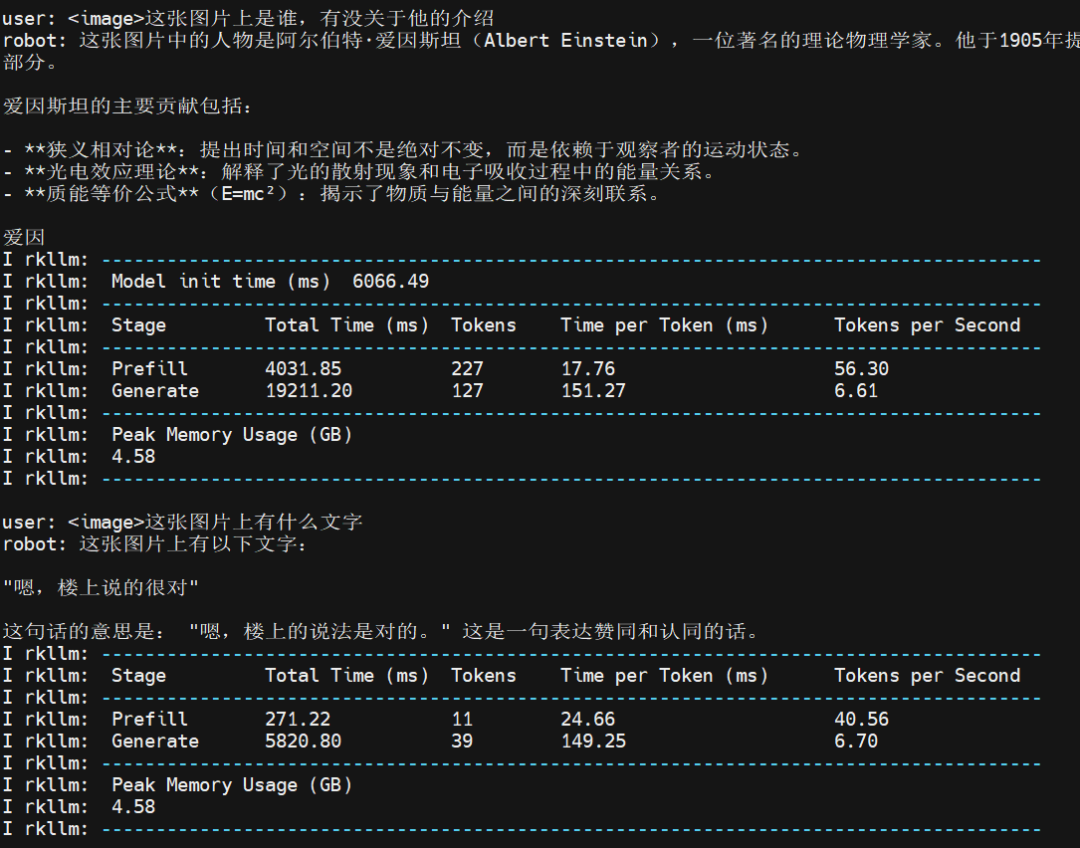
总得来说,模型第一次加载 6 秒钟,首次出词语也有体感上的慢,但是这之后速度就很稳定,而且很快,纯文字的速度更快一些。
结论
本文围绕瑞芯微 RK3576 开发板 NPU 对多模态 LLM 的支撑能力与性能展开测评,全面呈现其在端侧 AI 领域的价值。
端侧SLM在延迟、隐私与离线可用性上的优势显著,而 RK3576 凭借 8nm 制程、6TOPS自研NPU及动态稀疏化加速引擎,填补了旗舰与主流方案的市场空白。它针对2B-3B参数级模型专项优化,轻量化视觉任务算力利用率提升 18%,NPU功耗降低 22%,30% 的成本优势使其在多场景快速量产,中高端市场占有率环比增长 47%。
技术落地方面,RKNN 与 RKLLM SDK形成互补生态,RKNN 保障模型兼容性,RKLLM 通过量化优化、多模态支持等降低模型内存占用与推理延迟。实测中,RK3576 运行 Qwen2-VL-3B 模型时,纯文字交互 Token 生成稳定,多模态问答能精准识别图像元素,峰值内存占用 4.58GB ,在移动终端和工业场景可靠运行。
本文提供的环境准备、模型转换、代码适配等实操步骤,为开发者提供了可复现的部署方案。RK3576 在多场景展现良好兼容性与稳定性,能以低成本实现高准确率任务。
未来,RK3576“算力精准匹配场景”的设计理念或成中端AIoT核心方向,其在多维度的平衡,为端侧AI部署提供高性价比选择,助力边缘计算规模化应用。
RK3576 工作状态
MYD-LR3576-产品介绍-V1.1: https://dev.myir.cn/upload/files/product/20250211/17392600078427483.pdf
[2]rknn_model_zoo: 'https://github.com/airockchip/rknn_model_zoo'
[3]airockchip/rknn-llm: 'https://github.com/airockchip/rknn-llm'
[4]米尔开发平台: 'https://dev.myir.cn/'
[5]Rockchip_RKLLM_SDK_CN_1.2.1.pdf: 'https://github.com/airockchip/rknn-llm/blob/main/doc/Rockchip_RKLLM_SDK_CN_1.2.1.pdf'
[6]rknpu-driver: 'https://github.com/airockchip/rknn-llm/tree/main/rknpu-driver'
[7]Qwen2-VL_Demo: 'https://github.com/airockchip/rknn-llm/tree/main/examples/Qwen2-VL_Demo'
[8]Qwen2-VL_Demo: 'https://github.com/airockchip/rknn-llm/tree/main/examples/Qwen2-VL_Demo'
[9]Qwen2-VL-2B-Instruct: 'https://huggingface.co/Qwen/Qwen2-VL-2B-Instruct'
[10]rkllm_model_zoo: 'https://console.box.lenovo.com/l/l0tXb8'
[11]rkllm_model_zoo: 'https://console.box.lenovo.com/l/l0tXb8'
[12]Qwen2-VL-2B_Demo segfault RK3576 using 1.2.0 version: 'https://github.com/airockchip/rknn-llm/issues/336'



2025-08-28
米尔发表演讲,并携瑞萨RZ产品亮相2025 Elexcon深圳电子展
2025年8月26日-28日,Elexcon深圳国际电子展在深圳会展中心(福田)1号馆(展台号:1L30)盛大举行。作为全球电子产业链的重要盛会,展会汇聚创新技术与行业解决方案。米尔电子MYIR携RZ系列核心板、开发板等方案Demo亮相瑞萨嵌入式MCU/MPU生态专区,并发表主题演讲。技术盛宴:瑞萨RZ系列产品矩阵亮相展会上,米尔展示了基于RZ/G2L、RZ/G2UL、RZ/T2H的核心板
2025-08-28
留言领奖!2025 STM32研讨会即将启幕,米尔期待与你共会
2025年9月11日及9月17日,STM32研讨会将走进北京和上海,为大家深入解读STM32的中国战略,并围绕STM32在不同领域的最新产品布局和生态展开主题演讲,包括边缘人工智能、电源能源、无线连接、安全等,深入探讨STM32带来的前沿科技成果。同时,STM32还将携手业内多家合作伙伴,展示STM32在更多领域的解决方案及应用实例。欢迎开发者及工程师莅临现场,与ST专家面对面沟通交流,体验不同产
2025-08-28
Qwen2-VL-3B模型在米尔瑞芯微RK3576开发板NPU多模态部署指导与评测
关键词:瑞芯微 RK3576、NPU(神经网络处理器)、端侧小语言模型(SLM)、多模态 LLM、边缘 AI 部署、开发板、RKLLM随着大语言模型(LLM)技术的快速迭代,从云端集中式部署到端侧分布式运行的趋势日益明显。端侧小型语言模型(SLM)凭借低延迟、高隐私性和离线可用的独特优势,正在智能设备、边缘计算等场景中展现出巨大潜力。瑞芯微 RK3576 开发板作为一款聚焦边缘 AI 的硬件平台,
2025-08-14
12路1080P高清视频流,米尔RK3576开发板重塑视频处理极限
在智能视觉技术不断发展的今天,多路摄像数据的处理与传输已成为众多应用场景的核心需求。从智能安防监控领域的全面覆盖,到工业视觉处理网关的精准检测,再到车载环视融合平台的实时驾驶辅助以及智慧社区AI防控的快速响应,多路摄像数据的处理与传输已成为关键需求,而高效且低延时的解决方案则是实现这些应用的核心。目前多路摄像传输方案往往存在一定局限,接入路数有限,难以满足大规模监控场景的需求,且延迟较高,影响实时
2025-08-14
共建生态,米尔将出席2025安路科技FPGA技术沙龙
在数字化浪潮席卷全球的今天,FPGA技术正成为驱动创新的核心引擎。2025年8月21日,深圳将迎来一场聚焦FPGA技术与产业应用的盛会——2025安路科技FPGA技术沙龙。本次沙龙以“定制未来 共建生态”为主题,汇聚行业专家、企业代表及技术开发者,探讨前沿技术趋势,解锁定制化解决方案,共建开放共赢的FPGA生态圈!米尔作为领先的嵌入式处理器模组厂商,将携安路FPGA核心板和开发板亮相,并发表主题演
2025-08-08
如何在RK3576开发板上板端编译OpenCV并搭建应用
本文将介绍基于米尔电子MYD-LR3576开发板(米尔基于瑞芯微 RK3576开发板)的板端编译OpenCV及环境搭建方案的开发测试。摘自优秀创作者-短笛君RK3576具有如下配置:4× Cortex-A72(大核,主频最高 2.2GHz)4× Cortex-A53(小核,主频最高 1.8GHz)NPU(AI加速单元):独立 NPU,算力典型值6 TOPS(INT8)支持 TensorFlow L
2025-08-08
倒计时!米尔-安路飞龙派创意秀奖品等您领~~
创意秀活动进入倒计时阶段2025年米尔-安路飞龙派FPGA FPSoC创意开发大赛即将于8月15日正式收官(原定于6月15日,已延期到8月15日)。作为国产工业级FPGA领域的赛事,本次活动已吸引多支开发团队参与,基于MYD-YM90X开发板产出了众多创新解决方案。现距截稿仅剩7天,米尔特别提醒尚未提交作品的开发者把握最后几天,分享您的技术创作,申领米尔电子的奖品。活动链接:https://mp
2025-07-25
如何在RK3576开发板上运行TinyMaix :超轻量级推理框架--基于米尔MYD-LR3576开发板
本文将介绍基于米尔电子MYD-LR3576开发平台部署超轻量级推理框架方案:TinyMaix摘自优秀创作者-短笛君TinyMaix 是面向单片机的超轻量级的神经网络推理库,即 TinyML 推理库,可以让你在任意低资源MCU上运行轻量级深度学习模型。关键特性核心代码少于 400行(tm_layers.c+tm_model.c+arch_cpu.h),代码段(.text)少于3KB低内存消耗支持 I
2025-07-21
RKDC2025 丨米尔亮相第九届瑞芯微开发者大会,共绘工业数智新图景
2025年7月17日,第九届瑞芯微开发者大会(RKDC!2025)在福州海峡国际会展中心开幕。米尔电子作为瑞芯微IDH生态合作伙伴受邀出席此次盛会。米尔不仅为广大用户带来米尔基于RK35系列处理器的核心板和开发板/工控机,更展示了多款针对不同行业的解决方案,吸引了广大参观者前来参观了解。展台现场此次米尔电子重点展出了基于瑞芯微RK3576、RK3568、RK3562、RK3506处理器的核心板,搭
2025-07-10
米尔将出席瑞芯微第九届开发者大会
2025年7月17日~18日,第九届瑞芯微开发者大会(RKDC!2025)将在福州海峡国际会展中心盛大启幕。米尔电子作为瑞芯微IDH生态合作伙伴,将携RK系列核心板、开发板、解决方案等产品出席此次盛会。届时,诚邀您莅临现场参观指导(展位号:F11),共话AI新技术的浪潮,推动电子产品从“IoT功能设备”向“场景化智能终端的演进,见证技术突破与生态协同!